Bueno chicos, pues ya sí que sí... he aquí mi última entrada del blog sobre la asignatura de ETICs.
Hoy no vengo a hablaros de ningún tema con en las entradas anteriores, hoy voy a hacer una reflexión final sobre todo lo aprendido durante el curso de esta asignatura.
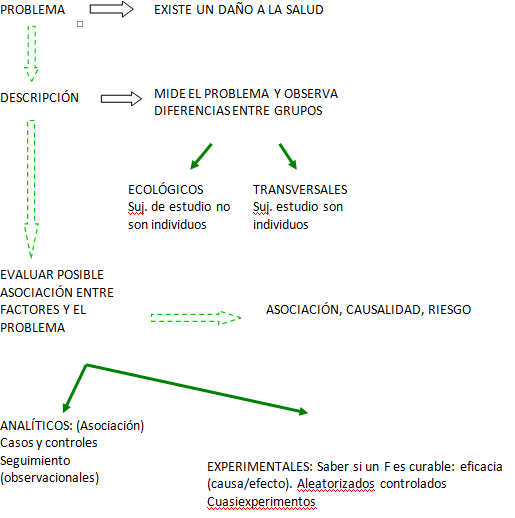
He de decir que a pesar de lo dura, complicada y pesada (¡sorry!) que se me ha hecho esta asignatura, me ha abierto mucho los ojos conociendo ámbitos de la Enfermería que no conocía, como es la investigación. Nunca me había llamado la atención eso de "INVESTIGACIÓN ENFERMERA", pero la verdad que era porque no sabía bien de que iba eso de la investigación. Suena como... no sé, algo aburrido y pesado, pero después de haber hecho nuestro propio trabajo de investigación en seminarios, me parece algo fascinante y con lo que puedes llegar a resolver muchos problemas, todo esto INVESTIGANDO.
Tanto es esto, que en el trabajo de investigación pedí consejos a mi madre (enfermera del Centro de Salud Ntra Sra de Gracia, Carmona) para que me ayudara a la hora de elegir un tema interesante y tal, le recordó tanto a su faceta estudiantil que ahora ha decidido especializarse en Investigación en Enfermería (ya lo podría haber hecho antes de que acabara el curso para ayudarme, jeje).
Bueno, solo me queda que decir que a pesar de pensar al principio del cuatrimestre que ETICs sería una asignatura absurda, no es así, creo que la investigación y la estadística es un papel súper fundamental en la Enfermería y al que no se le da todo el entusiasmo y atención que habría que darle.
Y, por sí me lee algún futuro estudiante de Enfermería, no dejes la asignatura de ETICs para el final, puede llegar a ser algo infernal...
Dicho esto me despido de este estupendo y maravilloso blog de ETICs (al que espero que mis profes pongan buena nota jijiji). Me gustaría seguir publicando entradas acerca de cosas interesantes que vaya descubriendo sobre Enfermería y la investigación, pero creo que la época de exámenes me lo va a poner un poco difícil. Nada chicos, NOS VEMOS A LA VUELTA!! Que tengáis un verano estupendiiiiisimo!!